

As most of you have already learned, LLMs are resource hogs for electricity and processing power in general. Recently, Sam Altman, CEO of OpenAI educated us that the processing power and electricity required for ChatGPT to simply process the words “please” and “thank you” costs the company millions per month. Because of the heavy resource load, LLMs are consistently finding creative ways to reduce the resource load.
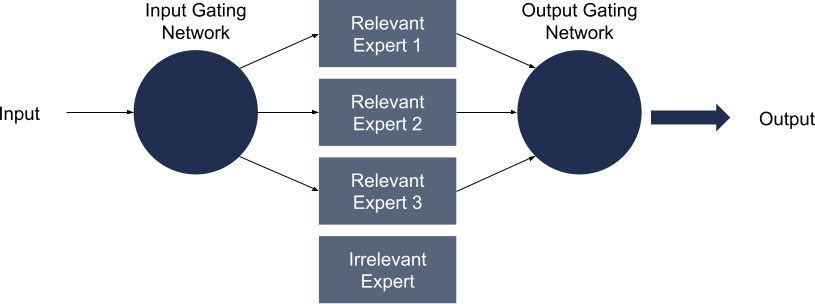
Mixture‑of‑Experts (MoE) is one of the methods LLMs are currently using to reduce resource load. MoE’s make queries exponentially more efficient. Each query is now routed to a subset of hyper‑focused “experts,” slashing required processing power and electricity cost while sharpening topical accuracy and speed.
GPT‑4 reportedly runs on eight internal 220‑billion‑parameter experts working in concert, delivering more than a trillion effective parameters without paying the trillion‑parameter power bill. In essence, this is like changing from a vehicle that gets 15 MPG in gas to 50 MPG.
What does this have to do with SEO? Search is changing under our feet, and so must our optimization strategies. What follows is a deep dive into why MoE matters in SEO and how to future‑proof your SEO by understanding MoE’s place in search.
Why MoE Matters for SEO
Traditional LLMs = all parameters, all the time.
MoE = only the specialists that matter.
A lightweight gating network inspects every incoming token, decides which experts can add the most value, and activates just those. In a sparse setup, the model may touch only 10‑20 percent of its parameters per inference.
MoE flow in LLM
The benefits stack up fast:
- Computational thrift: Hardware costs plummet because the whole model isn’t loaded on‑chip.
- Bigger virtual scale: You can field a trillion‑parameter “virtual capacity” while paying for a fraction of that size in VRAM.
- Sharper reasoning: Experts can be trained or fine‑tuned on narrow domains; finance math here, medical jargon there, so each slice of text is judged by specialists instead of amateurs.
- Faster iteration: When new data arrives, you can retrain or swap a single expert without disturbing the entire ensemble, shortening R&D cycles.
SEO’s are used to a single input going into a single system that delivers multiple possible responses via rankings. LLMs don’t operate that way.For the user, the experience feels like a smarter, snappier model. For search professionals, it creates an upstream relevance filter that never existed before.
Shift From Keywords to Expert Alignment

Under the classic web paradigm, you could wrestle for rank post‑index with backlinks, anchor text, content optimization, schema, etc. tweaks. An MoE‑powered search assistant changes the order of operations. Once content is embedded and scored semantically, a gating network decides if your text belongs inside “Expert #3: HVAC Thermodynamics” or “Expert #6: Consumer DIY.” If it lands in the wrong bin, or in no bin at all the downstream ranking stage never even sees you.
This is why I call MoE the new expert alignment game. Your tactical goal is no longer “beat Competitor X for Keyword Y.” It’s “be the clearest, most unambiguous signal for Expert Z’s domain of authority.” The traditional knobs still matter, but they matter only after alignment is won. Think of alignment as a more advanced version of relevance.
Three Immediate SEO Shake‑Ups
A. Niche Depth Outranks General Breadth
Because experts are topical, breadth dilutes confidence. An in‑depth teardown of “industrial HVAC belt tension tolerances” will outperform a generic “HVAC 101” guide even if the latter sports more backlinks. Why? The teardown maps crisply to a mechanical‑systems expert. The 101 guide straddles half a dozen domains, so the router hedges its bets or punts to a different expert entirely. Specialized hubs beat catch‑all silos.
Practical tip: Build vertical pillar pages with internal spokes that answer every sub‑question in the niche. The tighter the topical radius, the stronger the router signal.
B. Semantic Clarity Is Non‑Negotiable
Gating networks rely on embedding similarity, not raw keywords. That means they pay attention to how words relate in context. Clear headings, consistent entity references, and structured data act like neon arrows: “Route this text to the supply‑chain expert!” Ambiguity is punished; crisp semantics are rewarded.
Practical tip:
- Use H2/H3 tags that read like mini‑queries (“What Is Static Pressure?”).
- Identify entities with schema.org markup (<Organization>, <Person>, <Product>).
- Keep paragraphs tight: one idea, one intent.
C. Authority Moves Inside the Model
External authority signals (links, domain age) still govern crawling frequency and baseline trust. But once your text is ingested, it becomes part of the model’s internal long‑term memory. If Expert #4 was fine‑tuned on last quarter’s crawl, its internal weights now “remember” who wrote the definitive belt‑tension guide. Future queries are biased toward that memory even if competitor sites add stronger backlinks next week.
Practical tip: Publish high‑authority assets early in an emerging niche. Timing matters because snapshots of the web frozen into model checkpoints can persist for months.
Action Plan for the MoE Era
To translate theory into traffic, tighten your workflow around five concrete moves.
- Build Topic Clusters, Not One‑Offs
- Map a sub‑domain tree: each root page targets a broad entity; each branch post drills into edge cases, FAQs, specs.
- Interlink with descriptive anchor text so crawlers and routers see a cohesive package.
- Mark Up Everything
- Add JSON‑LD schema for FAQ, HowTo, Product, and Article.
- Include about and mentions properties to tie your page to recognized Wikidata or Wikipedia entities.
- List the author’s credentials; MoE experts trained on E‑E‑A‑T data use that signal.
- Write Like a Specialist
- Jargon is fine if it serves clarity. “Variable frequency drive” beats “fancy motor controller.”
- Avoid nuance drift: don’t mix beginner content with pro‑level tables on the same URL. Split pages.
- Probe the Models Regularly
- Run sample queries in ChatGPT, Claude, Gemini.
- Note which of your URLs (if any) appear or are cited.
- Adjust headings and intros until the assistant consistently chooses your answer snippet.
- Stay Agile
- Vendors rebalance experts to manage inference cost. Early GPT‑4 felt more verbose; today it’s more blunt because fewer experts fire per token. Track traffic from AI assistants and set up anomaly alerts.
Beyond SEO: Business and Content Implications
MoE doesn’t just reshape organic traffic; it shapes how brands are encoded in AI cognition. Consider three ripple effects:
- Content Localization: You can add a regional expert without touching the global model. For multinational sites, local pages in Japanese or Portuguese gain parity without bloating the core.
- Paid Search and PPC: If Bing Copilot or Google’s AI Overview routes commercial queries to MoE experts, ad auctions may bifurcate; one price for general terms, another for expert‑aligned slots.
- Product Development: Documentation, FAQs, and support threads now double as training data. Release notes written with expert‑friendly structure can cut customer‑support costs because AI agents answer more accurately.
Long term, we may see dynamic expert markets: swap‑in expert modules licensed from third‑party providers. Imagine leasing a “Legal‑Briefs‑2025” expert for your SaaS contracts page. When that becomes reality, aligning early will pay compounding dividends.
A Quick Case Example
A mid‑market equipment supplier asked me why their glossy “Comprehensive Guide to Industrial Fans” lost visibility in Gemini’s AI Overview. A scrape showed Gemini citing a niche mechanical blog instead. Diagnostics revealed the culprit. Their guide collapsed five different intents; fan sizing, belt tension, safety compliance, and maintenance schedules under one URL. We refactored into four laser‑focused pages, added HowTo schema for maintenance steps, and published a short spec sheet with structured tables. Within two weeks, the maintenance page and spec sheet were the sources Gemini cited for installation questions. Traffic from AI snippets rebounded 78 percent.
The Road Ahead
MoE isn’t a minor speed boost; it’s a paradigm shift from monolithic ranking to specialist curation. Every brand is now auditioning for placement in a panel of domain experts that live inside someone else’s model weights. The search victors of the next five years will publish content so surgically precise that a gating network can’t not call on it.
Time to assemble your own lineup of expert‑level pages before the competition captures the spotlight!
 I would love to hear from you. I am open to Full-Time Remote positions, specific client projects, and consultant work.
I would love to hear from you. I am open to Full-Time Remote positions, specific client projects, and consultant work.



